131 1300 0010
web的最大優勢之一是其開放性和分布式本質。這也是一大挑戰:數百萬站點,數千項主題,人們如何瀏覽內容并發現新的可信賴信息源?
Feedly對這一挑戰的解決方案是使用數據科學組織所有這些信息源,并幫助人們瀏覽主題。
本文介紹了[Feedly新的發現體驗]背后的一些技術,以及我從這一項目中學習到的經驗。
從用戶生成數據中學習主題
根據用戶加入新站點或博客時所屬的分類(數據經過匿名化處理),可以自動創建新的英語主題分類。
所以,如果你是在“tech”(技術)下加入The Verge和Engadget的45000人之一,那么你幫助創建了“tech”主題。
不過,這樣的主題列表仍然存在一些問題,主要是重復主題和“垃圾主題”。
想要理解我是如何訓練模型識別主題的,可以想像一個矩陣或者表格,其中有關于主題和信息源的數據。
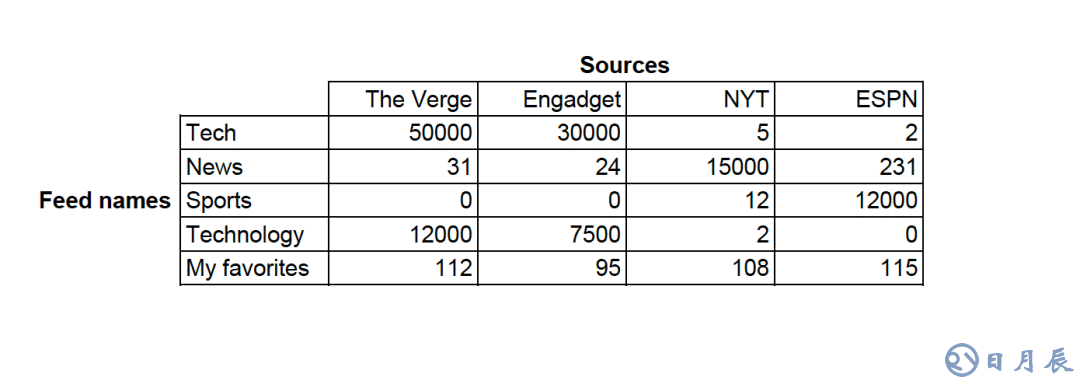
你注意到了上表第六行的“My favorites”(我的最愛)主題了沒有?這是一個極好的垃圾主題的例子,因為它不具有描述性。你可能也注意到了“tech”和“techonolgy”這一對重復主題。如果我們將矩陣擴展至10000+主題和100000+信息源,我們會看到很多這樣的垃圾主題和重復主題。
所以我們如何擺脫這些垃圾主題和重復主題呢?這正是數據清洗的價值所在。
在上表中,每行有一個數字數組,也稱為向量。所有數字同構的行意味著垃圾主題,而特定站點在行中顯示為峰值的是好主題。
一圖勝千言:
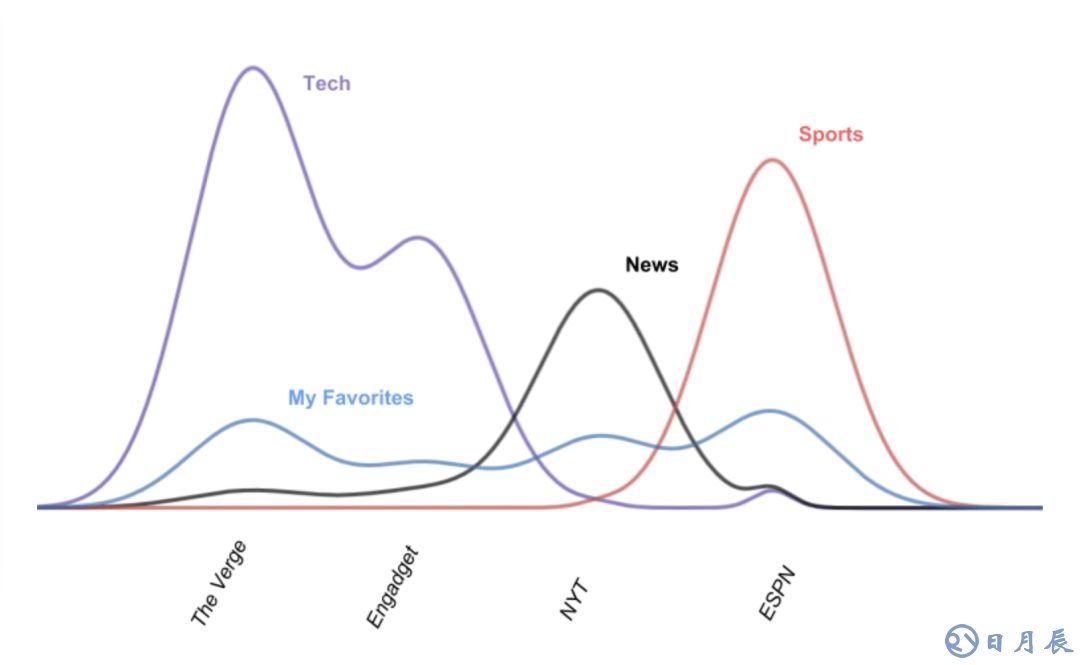
我們可以通過測量相應圖形的尖峰來檢測垃圾主題。從向量性質的角度來說,我們可以,比方說,測量最大數字和非零值數字的比值。
類似地,下面的圖形顯示了重復主題:

我們同樣根據向量的性質檢測這些重復主題。在我們的例子中,“Tech”向量的分量[50000, 30000, 5, 2]和“Technology”的[12000, 7500, 2, 0]在歸一化(將絕對數字轉換為百分比)后非常相似。我使用JS散度得出兩個向量的相似度。
一旦偵測出了相似向量,我們可以在系統中安全地合并兩者,并將搜索“technology”的用戶重定向至“tech”。
感謝使用Feedly的英語讀者的巨大社區,我們得以將所有數據轉換為一個整潔、去重的包含超過2500良好主題的列表。
我們很高興地報告,我們的分類足夠深入,包含“真菌學”這樣的主題!
鏈接的強度與同屬兩個主題的信息源數量成正比
主題樹:創建層次結構
既然我們的信息源已經有了豐富的主題標簽,下一個挑戰是引入連接相關主題的更好的組織系統。
有些主題是通用的(“tech”),而另一些則要專門一些(“iPad”)。“iPad”屬于“Apple”的子主題,“Apple”又是“Tech”的子主題,像這樣的主題層次結構的內部表示,有助于計算推薦。
我們使用模式匹配創建這樣的層次結構。下圖顯示了三個主題(左側)和與這些主題相關的信息源(右側)的連接。線越粗,將信息源置于這一主題下的用戶就越多。
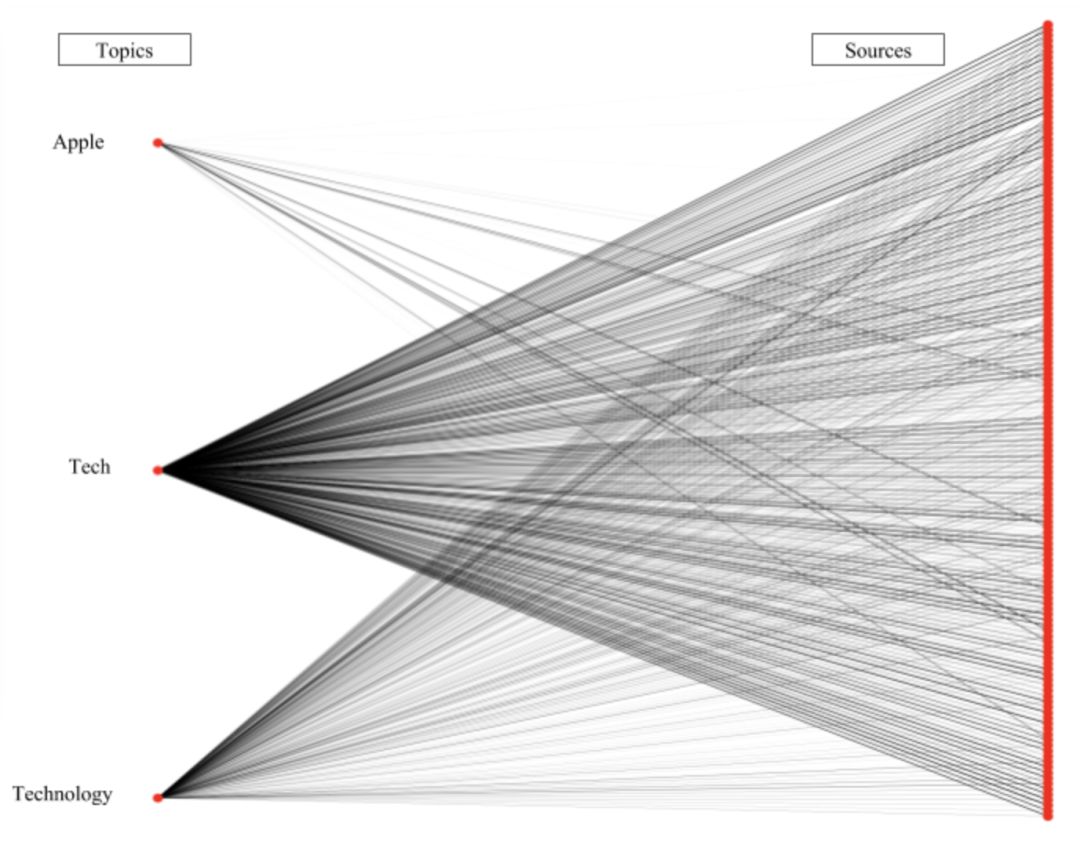
“Apple”連接“tech”主題信息源的一個子集,所以“Apple”是“tech”的子主題
上面的模式也確認了人們以大致相同的方式使用“tech”和“technology”。“technology”的線要細一點,因為人們較少使用這一術語。不過這兩個主題是重復的。同時,“Apple”看起來是“tech”的子主題:它連接了更少的信息源,而且它的連接同時也和“tech”相關。
基于這些模式,我們可以構建所有主題和子主題的樹形結構。

現在,如果你訪問Feedly的Discover(發現)頁面,你會找到一個特色主題列表。點擊任意主題即可開始瀏覽。相關主題有助于你進一步深入層次結構。
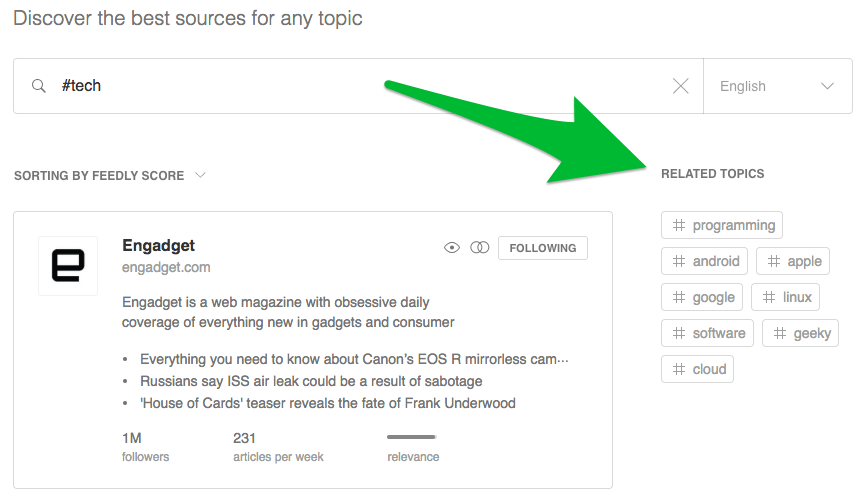
排列每個主題的推薦信息源
創建主題并組織為層次結構后,我們仍然需要決定推薦哪些信息源,以什么順序推薦。我們想要根據以下三個標準進行優化:
相關性 —— 用戶添加信息源至該主題與其他主題的比例
關注數 —— 多少用戶連接了這一信息源
粘度 —— 質量和關注的代理
前兩個標準很是直截了當。人們期望看到和他們瀏覽的主題相關的流行網站,同時常常需要折衷這兩個測度。
第三個標準更加主觀。它應該反映網站的質量,獨立于閱讀該站點的用戶絕對數量。事實上,我們相信,一些小眾站點可能讀者較少,但內容更好。
“信息源之戰”試驗
為了計算粘度評分,我們在Feedly社區中運行了一項試驗。我們選擇了一些和“tech”主題相關的信息源,并讓用戶投票更喜歡哪些信息源。
我們在一周內收集了25000張票,生成了這些站點的排名。我們尋找和用戶喜歡程度最相關的特征。
例如,在下表中,我們展示了信息源得分和閱讀該信息源的平均時間之間的關系(“read_time”,閱讀時間,相關性大致等于0.45)。相關性是正的,這意味著評分越高,人們花在該信息源上的時間大概就越長。這里例子中的其他特征同樣顯示了正相關性,因為它們都是好信息源的指標。我們的方法讓我們得以選出和投票結果最相關的特征。接著我們就可以加權組合這些特征,以稍微提升最好的那些信息源的排名。
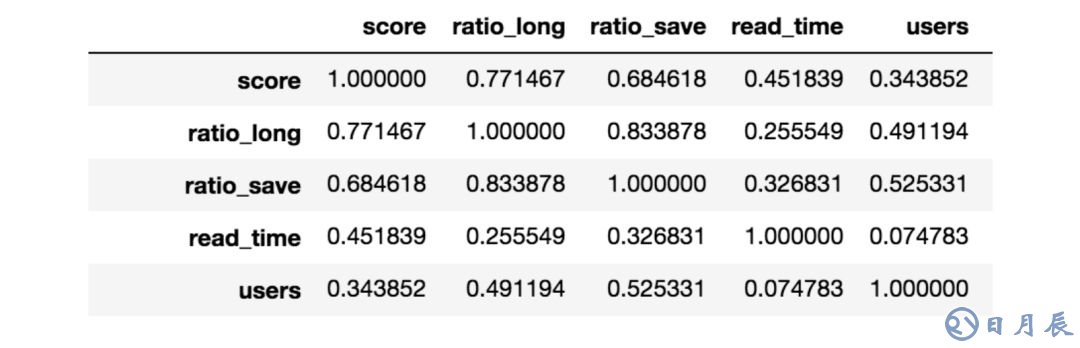
感謝所有為“信息源之戰”試驗投票的人。在Discover頁面瀏覽特色主題,或者搜索你最喜歡的主題的時候,都用到了這次試驗的結果。
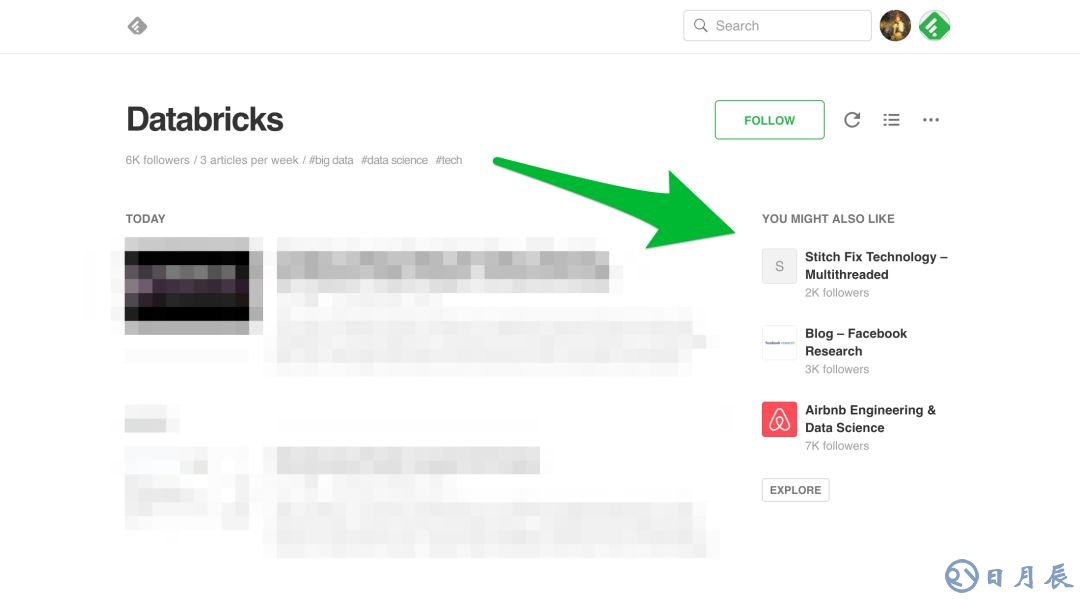
生成“你可能也喜歡”信息源和更多“相關主題”
相關主題不僅包括上面提到的子主題(取自層次結構),還包括基于item2vec協同過濾得到的主題。
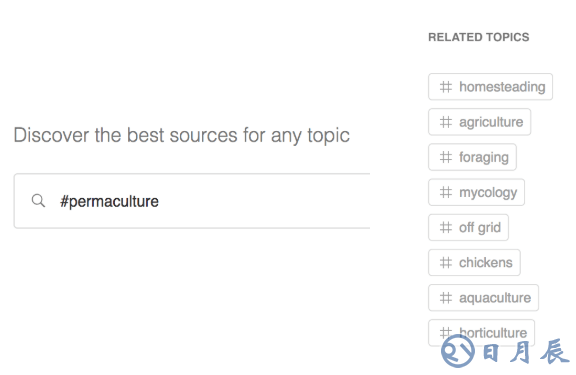
我們同樣基于item2vec技術,根據你已經關注的信息源,推薦“你可能也喜歡”(You Might Also Like)的信息源。
結語
十分感謝Feedly社區為發現項目所做的直接和間接貢獻。祝探索愉快!

