131 1300 0010
一、基本知識(shí)及現(xiàn)狀
從廣義上講只要能夠運(yùn)行人工智能算法的芯片都叫作 AI 芯片。但是通常意義上的 AI 芯片指的是針對(duì)人工智能算法做了特殊加速設(shè)計(jì)的芯片, 現(xiàn)階段, 這些人工智能算法一般以深度學(xué)習(xí)算法為主,也可以包括其它機(jī)器學(xué)習(xí)算法。

深度學(xué)習(xí)算法,通常是基于接收到的連續(xù)數(shù)值, 通過學(xué)習(xí)處理, 并輸出連續(xù)數(shù)值的過程,實(shí)質(zhì)上并不能完全模仿生物大腦的運(yùn)作機(jī)制。 基于這一現(xiàn)實(shí), 研究界還提出了 SNN(Spiking Neural Network,脈沖神經(jīng)網(wǎng)絡(luò)) 模型。 作為第三代神經(jīng)網(wǎng)絡(luò)模型, SNN 更貼近生物神經(jīng)網(wǎng)絡(luò)——除了神經(jīng)元和突觸模型更貼近生物神經(jīng)元與突觸之外, SNN 還將時(shí)域信息引入了計(jì)算模型。目前基于 SNN 的 AI 芯片主要以 IBM 的 TrueNorth、 Intel 的 Loihi 以及國內(nèi)的清華大學(xué)天機(jī)芯為代表。
1、AI 芯片發(fā)展歷程
從圖靈的論文《計(jì)算機(jī)器與智能》 和圖靈測(cè)試, 到最初級(jí)的神經(jīng)元模擬單元——感知機(jī), 再到現(xiàn)在多達(dá)上百層的深度神經(jīng)網(wǎng)絡(luò),人類對(duì)人工智能的探索從來就沒有停止過。 上世紀(jì)八十年代,多層神經(jīng)網(wǎng)絡(luò)和反向傳播算法的出現(xiàn)給人工智能行業(yè)點(diǎn)燃了新的火花。反向傳播的主要?jiǎng)?chuàng)新在于能將信息輸出和目標(biāo)輸出之間的誤差通過多層網(wǎng)絡(luò)往前一級(jí)迭代反饋,將最終的輸出收斂到某一個(gè)目標(biāo)范圍之內(nèi)。 1989 年貝爾實(shí)驗(yàn)室成功利用反向傳播算法,在多層神經(jīng)網(wǎng)絡(luò)開發(fā)了一個(gè)手寫郵編識(shí)別器。 1998 年 Yann LeCun 和 Yoshua Bengio 發(fā)表了手寫識(shí)別神經(jīng)網(wǎng)絡(luò)和反向傳播優(yōu)化相關(guān)的論文《Gradient-based learning applied to documentrecognition》,開創(chuàng)了卷積神經(jīng)網(wǎng)絡(luò)的時(shí)代。
此后,人工智能陷入了長時(shí)間的發(fā)展沉寂階段,直到 1997年 IBM的深藍(lán)戰(zhàn)勝國際象棋大師和 2011年 IBM的沃森智能系統(tǒng)在 Jeopardy節(jié)目中勝出,人工智能才又一次為人們所關(guān)注。 2016 年 Alpha Go 擊敗韓國圍棋九段職業(yè)選手,則標(biāo)志著人工智能的又一波高潮。從基礎(chǔ)算法、 底層硬件、 工具框架到實(shí)際應(yīng)用場(chǎng)景, 現(xiàn)階段的人工智能領(lǐng)域已經(jīng)全面開花。
作為人工智能核心的底層硬件 AI 芯片,也同樣經(jīng)歷了多次的起伏和波折,總體看來,AI 芯片的發(fā)展前后經(jīng)歷了四次大的變化,其發(fā)展歷程如圖所示。
(1) 2007 年以前, AI 芯片產(chǎn)業(yè)一直沒有發(fā)展成為成熟的產(chǎn)業(yè); 同時(shí)由于當(dāng)時(shí)算法、數(shù)據(jù)量等因素, 這個(gè)階段 AI 芯片并沒有特別強(qiáng)烈的市場(chǎng)需求,通用的 CPU 芯片即可滿足應(yīng)用需要。
(2) 隨著高清視頻、 VR、 AR游戲等行業(yè)的發(fā)展, GPU產(chǎn)品取得快速的突破; 同時(shí)人們發(fā)現(xiàn) GPU 的并行計(jì)算特性恰好適應(yīng)人工智能算法及大數(shù)據(jù)并行計(jì)算的需求,如 GPU 比之前傳統(tǒng)的 CPU在深度學(xué)習(xí)算法的運(yùn)算上可以提高幾十倍的效率,因此開始嘗試使用 GPU進(jìn)行人工智能計(jì)算。
(3) 進(jìn)入 2010 年后,云計(jì)算廣泛推廣,人工智能的研究人員可以通過云計(jì)算借助大量 CPU 和 GPU 進(jìn)行混合運(yùn)算,進(jìn)一步推進(jìn)了 AI 芯片的深入應(yīng)用,從而催生了各類 AI 芯片的研發(fā)與應(yīng)用。
(4)人工智能對(duì)于計(jì)算能力的要求不斷快速地提升,進(jìn)入 2015 年后, GPU 性能功耗比不高的特點(diǎn)使其在工作適用場(chǎng)合受到多種限制, 業(yè)界開始研發(fā)針對(duì)人工智能的專用芯片,以期通過更好的硬件和芯片架構(gòu),在計(jì)算效率、能耗比等性能上得到進(jìn)一步提升。
2、我國 AI 芯片發(fā)展情況
目前,我國的人工智能芯片行業(yè)發(fā)展尚處于起步階段。 長期以來,中國在 CPU、 GPU、DSP 處理器設(shè)計(jì)上一直處于追趕地位,絕大部分芯片設(shè)計(jì)企業(yè)依靠國外的 IP 核設(shè)計(jì)芯片,在自主創(chuàng)新上受到了極大的限制。 然而,人工智能的興起,無疑為中國在處理器領(lǐng)域?qū)崿F(xiàn)彎道超車提供了絕佳的機(jī)遇。
人工智能領(lǐng)域的應(yīng)用目前還處于面向行業(yè)應(yīng)用階段,生態(tài)上尚未形成壟斷,國產(chǎn)處理器廠商與國外競(jìng)爭(zhēng)對(duì)手在人工智能這一全新賽場(chǎng)上處在同一起跑線上,因此, 基于新興技術(shù)和應(yīng)用市場(chǎng),中國在建立人工智能生態(tài)圈方面將大有可為。
由于我國特殊的環(huán)境和市場(chǎng),國內(nèi) AI 芯片的發(fā)展目前呈現(xiàn)出百花齊放、百家爭(zhēng)鳴的態(tài)勢(shì), AI 芯片的應(yīng)用領(lǐng)域也遍布股票交易、金融、商品推薦、安防、早教機(jī)器人以及無人駕駛等眾多領(lǐng)域,催生了大量的人工智能芯片創(chuàng)業(yè)公司,如地平線、深鑒科技、中科寒武紀(jì)等。
盡管如此, 國內(nèi)公司卻并未如國外大公司一樣形成市場(chǎng)規(guī)模, 反而出現(xiàn)各自為政的散裂發(fā)展現(xiàn)狀。除了新興創(chuàng)業(yè)公司,國內(nèi)研究機(jī)構(gòu)如北京大學(xué)、清華大學(xué)、中國科學(xué)院等在AI 芯片領(lǐng)域都有深入研究;而其他公司如百度和比特大陸等, 2017 年也有一些成果發(fā)布。可以預(yù)見,未來誰先在人工智能領(lǐng)域掌握了生態(tài)系統(tǒng),誰就掌握住了這個(gè)產(chǎn)業(yè)的主動(dòng)權(quán)。
3、AI學(xué)者概況
基于來自清華大學(xué)AMiner 人才庫數(shù)據(jù),全球人工智能芯片領(lǐng)域?qū)W者分布如圖所示, 從圖中可以看到, 人工智能芯片領(lǐng)域的學(xué)者主要分布在北美洲,其次是歐洲。 中國對(duì)人工智能芯片的研究緊跟其后,南美洲、非洲和大洋洲人才相對(duì)比較匱乏。
按國家進(jìn)行統(tǒng)計(jì)來看美國是人工智能芯片領(lǐng)域科技發(fā)展的核心。 英國的人數(shù)緊排在美國之后。其他的專家主要分布在中國、 德國、 加拿大、意大利和日本 。
對(duì)全球人工智能芯片領(lǐng)域最具影響力的 1000 人的遷徙路徑進(jìn)行了統(tǒng)計(jì)分析,得出下圖所示的各國人才逆順差對(duì)比。
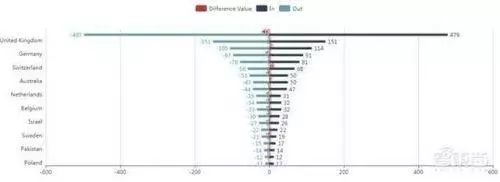
可以看出,各國人才的流失和引進(jìn)是相對(duì)比較均衡的,其中美國為人才流動(dòng)大國,人才輸入和輸出幅度都大幅度領(lǐng)先。英國、 中國、 德國和瑞士等國次于美國,但各國之間人才流動(dòng)相差并不明顯。
二、AI 芯片的分類及技術(shù)
人工智能芯片目前有兩種發(fā)展路徑:一種是延續(xù)傳統(tǒng)計(jì)算架構(gòu),加速硬件計(jì)算能力,主要以 3 種類型的芯片為代表,即 GPU、 FPGA、 ASIC,但 CPU依舊發(fā)揮著不可替代的作用;另一種是顛覆經(jīng)典的馮·諾依曼計(jì)算架構(gòu),采用類腦神經(jīng)結(jié)構(gòu)來提升計(jì)算能力, 以 IBM TrueNorth 芯片為代表。
1、傳統(tǒng)的 CPU
計(jì)算機(jī)工業(yè)從 1960 年代早期開始使用 CPU 這個(gè)術(shù)語。迄今為止, CPU 從形態(tài)、設(shè)計(jì)到實(shí)現(xiàn)都已發(fā)生了巨大的變化,但是其基本工作原理卻一直沒有大的改變。 通常 CPU 由控制器和運(yùn)算器這兩個(gè)主要部件組成。 傳統(tǒng)的 CPU 內(nèi)部結(jié)構(gòu)圖如圖 3 所示, 從圖中我們可以看到:實(shí)質(zhì)上僅單獨(dú)的 ALU 模塊(邏輯運(yùn)算單元)是用來完成數(shù)據(jù)計(jì)算的,其他各個(gè)模塊的存在都是為了保證指令能夠一條接一條的有序執(zhí)行。這種通用性結(jié)構(gòu)對(duì)于傳統(tǒng)的編程計(jì)算模式非常適合,同時(shí)可以通過提升 CPU 主頻(提升單位時(shí)間內(nèi)執(zhí)行指令的條數(shù))來提升計(jì)算速度。
但對(duì)于深度學(xué)習(xí)中的并不需要太多的程序指令、 卻需要海量數(shù)據(jù)運(yùn)算的計(jì)算需求, 這種結(jié)構(gòu)就顯得有些力不從心。尤其是在功耗限制下, 無法通過無限制的提升 CPU 和內(nèi)存的工作頻率來加快指令執(zhí)行速度, 這種情況導(dǎo)致 CPU 系統(tǒng)的發(fā)展遇到不可逾越的瓶頸。
2、并行加速計(jì)算的 GPU
GPU 作為最早從事并行加速計(jì)算的處理器,相比 CPU 速度快, 同時(shí)比其他加速器芯片編程靈活簡(jiǎn)單。
傳統(tǒng)的 CPU 之所以不適合人工智能算法的執(zhí)行,主要原因在于其計(jì)算指令遵循串行執(zhí)行的方式,沒能發(fā)揮出芯片的全部潛力。與之不同的是, GPU 具有高并行結(jié)構(gòu),在處理圖形數(shù)據(jù)和復(fù)雜算法方面擁有比 CPU 更高的效率。對(duì)比 GPU 和 CPU 在結(jié)構(gòu)上的差異, CPU大部分面積為控制器和寄存器,而 GPU 擁有更ALU(ARITHMETIC LOGIC UNIT,邏輯運(yùn)算單元)用于數(shù)據(jù)處理,這樣的結(jié)構(gòu)適合對(duì)密集型數(shù)據(jù)進(jìn)行并行處理, CPU 與 GPU 的結(jié)構(gòu)對(duì)比如圖 所示。程序在 GPU系統(tǒng)上的運(yùn)行速度相較于單核 CPU往往提升幾十倍乃至上千倍。隨著英偉達(dá)、 AMD 等公司不斷推進(jìn)其對(duì) GPU 大規(guī)模并行架構(gòu)的支持,面向通用計(jì)算的 GPU(即GPGPU, GENERAL PURPOSE GPU,通用計(jì)算圖形處理器)已成為加速可并行應(yīng)用程序的重要手段。
GPU 的發(fā)展歷程可分為 3 個(gè)階段, 發(fā)展歷程如圖所示:
第 一 代 GPU(1999 年 以 前 ) , 部 分 功 能 從 CPU 分 離 , 實(shí) 現(xiàn) 硬 件 加 速 , 以GE(GEOMETRY ENGINE)為代表,只能起到 3D 圖像處理的加速作用,不具有軟件編程特性。
第二代 GPU(1999-2005 年), 實(shí)現(xiàn)進(jìn)一步的硬件加速和有限的編程性。 1999 年,英偉達(dá)發(fā)布了“專為執(zhí)行復(fù)雜的數(shù)學(xué)和幾何計(jì)算的” GeForce256 圖像處理芯片,將更多的晶體管用作執(zhí)行單元, 而不是像 CPU 那樣用作復(fù)雜的控制單元和緩存,將 T&L(TRANSFORM AND LIGHTING)等功能從 CPU 分離出來,實(shí)現(xiàn)了快速變換,這成為 GPU 真正出現(xiàn)的標(biāo)志。之后幾年, GPU 技術(shù)快速發(fā)展,運(yùn)算速度迅速超過 CPU。 2001 年英偉達(dá)和 ATI 分別推出的GEFORCE3 和 RADEON 8500,圖形硬件的流水線被定義為流處理器,出現(xiàn)了頂點(diǎn)級(jí)可編程性,同時(shí)像素級(jí)也具有有限的編程性,但 GPU 的整體編程性仍然比較有限。
第三代 GPU(2006年以后), GPU實(shí)現(xiàn)方便的編程環(huán)境創(chuàng)建, 可以直接編寫程序。 2006年英偉達(dá)與 ATI分別推出了 CUDA(Compute United Device Architecture,計(jì)算統(tǒng)一設(shè)備架構(gòu))編程環(huán)境和 CTM(CLOSE TO THE METAL)編程環(huán)境, 使得 GPU 打破圖形語言的局限成為真正的并行數(shù)據(jù)處理超級(jí)加速器。
2008 年,蘋果公司提出一個(gè)通用的并行計(jì)算編程平臺(tái) OPENCL(OPEN COMPUTING LANGUAGE,開放運(yùn)算語言),與 CUDA 綁定在英偉達(dá)的顯卡上不同,OPENCL 和具體的計(jì)算設(shè)備無關(guān)。
目前, GPU 已經(jīng)發(fā)展到較為成熟的階段。谷歌、 FACEBOOK、微軟、 TWITTER 和百度等公司都在使用 GPU 分析圖片、視頻和音頻文件,以改進(jìn)搜索和圖像標(biāo)簽等應(yīng)用功能。此外,很多汽車生產(chǎn)商也在使用 GPU 芯片發(fā)展無人駕駛。 不僅如此, GPU 也被應(yīng)用于VR/AR 相關(guān)的產(chǎn)業(yè)。
但是 GPU也有一定的局限性。 深度學(xué)習(xí)算法分為訓(xùn)練和推斷兩部分, GPU 平臺(tái)在算法訓(xùn)練上非常高效。但在推斷中對(duì)于單項(xiàng)輸入進(jìn)行處理的時(shí)候,并行計(jì)算的優(yōu)勢(shì)不能完全發(fā)揮出來。
3、半定制化的 FPGA
FPGA 是在 PAL、 GAL、 CPLD 等可編程器件基礎(chǔ)上進(jìn)一步發(fā)展的產(chǎn)物。用戶可以通過燒入 FPGA 配置文件來定義這些門電路以及存儲(chǔ)器之間的連線。這種燒入不是一次性的,比如用戶可以把 FPGA 配置成一個(gè)微控制器 MCU,使用完畢后可以編輯配置文件把同一個(gè)FPGA 配置成一個(gè)音頻編解碼器。因此, 它既解決了定制電路靈活性的不足,又克服了原有可編程器件門電路數(shù)有限的缺點(diǎn)。
FPGA 可同時(shí)進(jìn)行數(shù)據(jù)并行和任務(wù)并行計(jì)算,在處理特定應(yīng)用時(shí)有更加明顯的效率提升。對(duì)于某個(gè)特定運(yùn)算,通用 CPU 可能需要多個(gè)時(shí)鐘周期; 而 FPGA 可以通過編程重組電路,直接生成專用電路,僅消耗少量甚至一次時(shí)鐘周期就可完成運(yùn)算。
此外,由于 FPGA的靈活性,很多使用通用處理器或 ASIC難以實(shí)現(xiàn)的底層硬件控制操作技術(shù), 利用 FPGA 可以很方便的實(shí)現(xiàn)。這個(gè)特性為算法的功能實(shí)現(xiàn)和優(yōu)化留出了更大空間。同時(shí) FPGA 一次性成本(光刻掩模制作成本)遠(yuǎn)低于 ASIC,在芯片需求還未成規(guī)模、深度學(xué)習(xí)算法暫未穩(wěn)定, 需要不斷迭代改進(jìn)的情況下,利用 FPGA 芯片具備可重構(gòu)的特性來實(shí)現(xiàn)半定制的人工智能芯片是最佳選擇之一。
功耗方面,從體系結(jié)構(gòu)而言, FPGA 也具有天生的優(yōu)勢(shì)。傳統(tǒng)的馮氏結(jié)構(gòu)中,執(zhí)行單元(如 CPU 核)執(zhí)行任意指令,都需要有指令存儲(chǔ)器、譯碼器、各種指令的運(yùn)算器及分支跳轉(zhuǎn)處理邏輯參與運(yùn)行, 而 FPGA 每個(gè)邏輯單元的功能在重編程(即燒入)時(shí)就已經(jīng)確定,不需要指令,無需共享內(nèi)存,從而可以極大的降低單位執(zhí)行的功耗,提高整體的能耗比。
由于 FPGA 具備靈活快速的特點(diǎn), 因此在眾多領(lǐng)域都有替代 ASIC 的趨勢(shì)。 FPGA 在人工智能領(lǐng)域的應(yīng)用如圖所示。
4、全定制化的 ASIC
目前以深度學(xué)習(xí)為代表的人工智能計(jì)算需求,主要采用 GPU、 FPGA 等已有的適合并行計(jì)算的通用芯片來實(shí)現(xiàn)加速。在產(chǎn)業(yè)應(yīng)用沒有大規(guī)模興起之時(shí),使用這類已有的通用芯片可以避免專門研發(fā)定制芯片(ASIC) 的高投入和高風(fēng)險(xiǎn)。但是,由于這類通用芯片設(shè)計(jì)初衷并非專門針對(duì)深度學(xué)習(xí),因而天然存在性能、 功耗等方面的局限性。隨著人工智能應(yīng)用規(guī)模的擴(kuò)大,這類問題日益突顯。
GPU 作為圖像處理器, 設(shè)計(jì)初衷是為了應(yīng)對(duì)圖像處理中的大規(guī)模并行計(jì)算。因此,在應(yīng)用于深度學(xué)習(xí)算法時(shí),有三個(gè)方面的局限性:
第一,應(yīng)用過程中無法充分發(fā)揮并行計(jì)算優(yōu)勢(shì)。 深度學(xué)習(xí)包含訓(xùn)練和推斷兩個(gè)計(jì)算環(huán)節(jié), GPU 在深度學(xué)習(xí)算法訓(xùn)練上非常高效, 但對(duì)于單一輸入進(jìn)行推斷的場(chǎng)合, 并行度的優(yōu)勢(shì)不能完全發(fā)揮。
第二, 無法靈活配置硬件結(jié)構(gòu)。 GPU 采用 SIMT 計(jì)算模式, 硬件結(jié)構(gòu)相對(duì)固定。
目前深度學(xué)習(xí)算法還未完全穩(wěn)定,若深度學(xué)習(xí)算法發(fā)生大的變化, GPU 無法像 FPGA 一樣可以靈活的配制硬件結(jié)構(gòu)。 第三,運(yùn)行深度學(xué)習(xí)算法能效低于 FPGA。
盡管 FPGA 倍受看好,甚至新一代百度大腦也是基于 FPGA 平臺(tái)研發(fā),但其畢竟不是專門為了適用深度學(xué)習(xí)算法而研發(fā),實(shí)際應(yīng)用中也存在諸多局限:
第一,基本單元的計(jì)算能力有限。為了實(shí)現(xiàn)可重構(gòu)特性, FPGA 內(nèi)部有大量極細(xì)粒度的基本單元,但是每個(gè)單元的計(jì)算能力(主要依靠 LUT 查找表)都遠(yuǎn)遠(yuǎn)低于 CPU 和 GPU 中的 ALU 模塊;
第二、 計(jì)算資源占比相對(duì)較低。 為實(shí)現(xiàn)可重構(gòu)特性, FPGA 內(nèi)部大量資源被用于可配置的片上路由與連線;
第三,速度和功耗相對(duì)專用定制芯片(ASIC)仍然存在不小差距;
第四, FPGA 價(jià)格較為昂貴,在規(guī)模放量的情況下單塊 FPGA 的成本要遠(yuǎn)高于專用定制芯片。
因此,隨著人工智能算法和應(yīng)用技術(shù)的日益發(fā)展,以及人工智能專用芯片 ASIC產(chǎn)業(yè)環(huán)境的逐漸成熟, 全定制化人工智能 ASIC也逐步體現(xiàn)出自身的優(yōu)勢(shì),從事此類芯片研發(fā)與應(yīng)用的國內(nèi)外比較有代表性的公司如圖所示。
深度學(xué)習(xí)算法穩(wěn)定后, AI 芯片可采用 ASIC 設(shè)計(jì)方法進(jìn)行全定制, 使性能、功耗和面積等指標(biāo)面向深度學(xué)習(xí)算法做到最優(yōu)。
5、類腦芯片
類腦芯片不采用經(jīng)典的馮·諾依曼架構(gòu), 而是基于神經(jīng)形態(tài)架構(gòu)設(shè)計(jì),以 IBM Truenorth為代表。 IBM 研究人員將存儲(chǔ)單元作為突觸、計(jì)算單元作為神經(jīng)元、傳輸單元作為軸突搭建了神經(jīng)芯片的原型。
目前, Truenorth 用三星 28nm 功耗工藝技術(shù),由 54 億個(gè)晶體管組成的芯片構(gòu)成的片上網(wǎng)絡(luò)有 4096 個(gè)神經(jīng)突觸核心,實(shí)時(shí)作業(yè)功耗僅為 70mW。由于神經(jīng)突觸要求權(quán)重可變且要有記憶功能, IBM 采用與 CMOS 工藝兼容的相變非揮發(fā)存儲(chǔ)器(PCM)的技術(shù)實(shí)驗(yàn)性的實(shí)現(xiàn)了新型突觸,加快了商業(yè)化進(jìn)程。
三、AI芯片產(chǎn)業(yè)及趨勢(shì)

1、AI芯片應(yīng)用領(lǐng)域
隨著人工智能芯片的持續(xù)發(fā)展,應(yīng)用領(lǐng)域會(huì)隨時(shí)間推移而不斷向多維方向發(fā)展,這里我們選擇目前發(fā)展比較集中的幾個(gè)行業(yè)做相關(guān)的介紹。
AI芯片目前比較集中的應(yīng)用領(lǐng)域
(1)智能手機(jī)
2017 年 9 月,華為在德國柏林消費(fèi)電子展發(fā)布了麒麟 970 芯片,該芯片搭載了寒武紀(jì)的 NPU,成為“全球首款智能手機(jī)移動(dòng)端 AI 芯片” ; 2017 年 10 月中旬 Mate10 系列新品(該系列手機(jī)的處理器為麒麟 970)上市。搭載了 NPU 的華為 Mate10 系列智能手機(jī)具備了較強(qiáng)的深度學(xué)習(xí)、本地端推斷能力,讓各類基于深度神經(jīng)網(wǎng)絡(luò)的攝影、圖像處理應(yīng)用能夠?yàn)橛脩籼峁└油昝赖捏w驗(yàn)。
而蘋果發(fā)布以 iPhone X 為代表的手機(jī)及它們內(nèi)置的 A11 Bionic 芯片。A11 Bionic 中自主研發(fā)的雙核架構(gòu) Neural Engine(神經(jīng)網(wǎng)絡(luò)處理引擎),它每秒處理相應(yīng)神經(jīng)網(wǎng)絡(luò)計(jì)算需求的次數(shù)可達(dá) 6000 億次。這個(gè) Neural Engine 的出現(xiàn),讓 A11 Bionic 成為一塊真正的 AI 芯片。 A11 Bionic 大大提升了 iPhone X 在拍照方面的使用體驗(yàn),并提供了一些富有創(chuàng)意的新用法。
(2)ADAS(高級(jí)輔助駕駛系統(tǒng))
ADAS 是最吸引大眾眼球的人工智能應(yīng)用之一, 它需要處理海量的由激光雷達(dá)、毫米波雷達(dá)、攝像頭等傳感器采集的實(shí)時(shí)數(shù)據(jù)。相對(duì)于傳統(tǒng)的車輛控制方法,智能控制方法主要體現(xiàn)在對(duì)控制對(duì)象模型的運(yùn)用和綜合信息學(xué)習(xí)運(yùn)用上,包括神經(jīng)網(wǎng)絡(luò)控制和深度學(xué)習(xí)方法等,得益于 AI 芯片的飛速發(fā)展, 這些算法已逐步在車輛控制中得到應(yīng)用。
(3)CV(計(jì)算機(jī)視覺(Computer Vision) 設(shè)備
需要使用計(jì)算機(jī)視覺技術(shù)的設(shè)備,如智能攝像頭、無人機(jī)、 行車記錄儀、人臉識(shí)別迎賓機(jī)器人以及智能手寫板等設(shè)備, 往往都具有本地端推斷的需要,如果僅能在聯(lián)網(wǎng)下工作,無疑將帶來糟糕的體驗(yàn)。而計(jì)算機(jī)視覺技術(shù)目前看來將會(huì)成為人工智能應(yīng)用的沃土之一,計(jì)算機(jī)視覺芯片將擁有廣闊的市場(chǎng)前景。
(4) VR 設(shè)備
VR 設(shè)備芯片的代表為 HPU 芯片, 是微軟為自身 VR 設(shè)備 Hololens 研發(fā)定制的。 這顆由臺(tái)積電代工的芯片能同時(shí)處理來自 5個(gè)攝像頭、 1個(gè)深度傳感器以及運(yùn)動(dòng)傳感器的數(shù)據(jù),并具備計(jì)算機(jī)視覺的矩陣運(yùn)算和 CNN 運(yùn)算的加速功能。這使得 VR 設(shè)備可重建高質(zhì)量的人像 3D 影像,并實(shí)時(shí)傳送到任何地方。
(5)語音交互設(shè)備
語音交互設(shè)備芯片方面,國內(nèi)有啟英泰倫以及云知聲兩家公司,其提供的芯片方案均內(nèi)置了為語音識(shí)別而優(yōu)化的深度神經(jīng)網(wǎng)絡(luò)加速方案,實(shí)現(xiàn)設(shè)備的語音離線識(shí)別。穩(wěn)定的識(shí)別能力為語音技術(shù)的落地提供了可能; 與此同時(shí),語音交互的核心環(huán)節(jié)也取得重大突破。語音識(shí)別環(huán)節(jié)突破了單點(diǎn)能力,從遠(yuǎn)場(chǎng)識(shí)別,到語音分析和語義理解有了重大突破,呈現(xiàn)出一種整體的交互方案。
(6)機(jī)器人
無論是家居機(jī)器人還是商用服務(wù)機(jī)器人均需要專用軟件+芯片的人工智能解決方案,這方面典型公司有由前百度深度學(xué)習(xí)實(shí)驗(yàn)室負(fù)責(zé)人余凱創(chuàng)辦的地平線機(jī)器人,當(dāng)然地平線機(jī)器人除此之外,還提供 ADAS、智能家居等其他嵌入式人工智能解決方案。
2、AI芯片國內(nèi)外代表性企業(yè)

本篇將介紹目前人工智能芯片技術(shù)領(lǐng)域的國內(nèi)外代表性企業(yè)。文中排名不分先后。人工智能芯片技術(shù)領(lǐng)域的國內(nèi)代表性企業(yè)包括中科寒武紀(jì)、中星微、地平線機(jī)器人、深鑒科技、 靈汐科技、 啟英泰倫、百度、華為等,國外包括英偉達(dá)、 AMD、 Google、高通、Nervana Systems、 Movidius、 IBM、 ARM、 CEVA、 MIT/Eyeriss、蘋果、三星等。
中科寒武紀(jì)
寒武紀(jì)科技成立于 2016 年,總部在北京,創(chuàng)始人是中科院計(jì)算所的陳天石、陳云霽兄弟,公司致力于打造各類智能云服務(wù)器、智能終端以及智能機(jī)器人的核心處理器芯片。阿里巴巴創(chuàng)投、聯(lián)想創(chuàng)投、國科投資、中科圖靈、元禾原點(diǎn)、涌鏵投資聯(lián)合投資,為全球 AI芯片領(lǐng)域第一個(gè)獨(dú)角獸初創(chuàng)公司。
寒武紀(jì)是全球第一個(gè)成功流片并擁有成熟產(chǎn)品的 AI 芯片公司,擁有終端 AI 處理器 IP和云端高性能 AI 芯片兩條產(chǎn)品線。 2016 年發(fā)布的寒武紀(jì) 1A 處理器(Cambricon-1A) 是世界首款商用深度學(xué)習(xí)專用處理器,面向智能手機(jī)、安防監(jiān)控、無人機(jī)、可穿戴設(shè)備以及智能駕駛等各類終端設(shè)備,在運(yùn)行主流智能算法時(shí)性能功耗比全面超越傳統(tǒng)處理器。
中星微
1999 年, 由多位來自硅谷的博士企業(yè)家在北京中關(guān)村科技園區(qū)創(chuàng)建了中星微電子有限公司, 啟動(dòng)并承擔(dān)了國家戰(zhàn)略項(xiàng)目——“星光中國芯工程”,致力于數(shù)字多媒體芯片的開發(fā)、設(shè)計(jì)和產(chǎn)業(yè)化。
2016 年初,中星微推出了全球首款集成了神經(jīng)網(wǎng)絡(luò)處理器(NPU)的 SVAC 視頻編解碼 SoC,使得智能分析結(jié)果可以與視頻數(shù)據(jù)同時(shí)編碼,形成結(jié)構(gòu)化的視頻碼流。該技術(shù)被廣泛應(yīng)用于視頻監(jiān)控?cái)z像頭,開啟了安防監(jiān)控智能化的新時(shí)代。自主設(shè)計(jì)的嵌入式神經(jīng)網(wǎng)絡(luò)處理器(NPU)采用了“數(shù)據(jù)驅(qū)動(dòng)并行計(jì)算” 架構(gòu),專門針對(duì)深度學(xué)習(xí)算法進(jìn)行了優(yōu)化,具備高性能、低功耗、高集成度、小尺寸等特點(diǎn),特別適合物聯(lián)網(wǎng)前端智能的需求。
地平線機(jī)器人(Horizon Robotics)
地平線機(jī)器人成立于 2015 年,總部在北京,創(chuàng)始人是前百度深度學(xué)習(xí)研究院負(fù)責(zé)人余凱。BPU(BrainProcessing Unit) 是地平線機(jī)器人自主設(shè)計(jì)研發(fā)的高效人工智能處理器架構(gòu)IP,支持 ARM/GPU/FPGA/ASIC 實(shí)現(xiàn),專注于自動(dòng)駕駛、人臉圖像辨識(shí)等專用領(lǐng)域。
2017年,地平線發(fā)布基于高斯架構(gòu)的嵌入式人工智能解決方案,將在智能駕駛、智能生活、公共安防三個(gè)領(lǐng)域進(jìn)行應(yīng)用,第一代 BPU芯片“盤古” 目前已進(jìn)入流片階段,預(yù)計(jì)在 2018年下半年推出,能支持 1080P 的高清圖像輸入,每秒鐘處理 30 幀,檢測(cè)跟蹤數(shù)百個(gè)目標(biāo)。地平線的第一代 BPU 采用 TSMC 的 40nm工藝,相對(duì)于傳統(tǒng) CPU/GPU, 能效可以提升 2~3 個(gè)數(shù)量級(jí)(100~1,000 倍左右)。
深鑒科技
深鑒科技成立于 2016 年,總部在北京。由清華大學(xué)與斯坦福大學(xué)的世界頂尖深度學(xué)習(xí)硬件研究者創(chuàng)立。深鑒科技于 2018 年 7 月被賽靈思收購。深鑒科技將其開發(fā)的基于 FPGA 的神經(jīng)網(wǎng)絡(luò)處理器稱為 DPU。
到目前為止,深鑒公開發(fā)布了兩款 DPU:亞里士多德架構(gòu)和笛卡爾架構(gòu),其中,亞里士多德架構(gòu)是針對(duì)卷積神經(jīng)網(wǎng)絡(luò) CNN 而設(shè)計(jì);笛卡爾架構(gòu)專為處理 DNN/RNN 網(wǎng)絡(luò)而設(shè)計(jì),可對(duì)經(jīng)過結(jié)構(gòu)壓縮后的稀疏神經(jīng)網(wǎng)絡(luò)進(jìn)行極致高效的硬件加速。相對(duì)于 Intel XeonCPU 與 Nvidia TitanX GPU,應(yīng)用笛卡爾架構(gòu)的處理器在計(jì)算速度上分別提高 189 倍與 13 倍,具有 24,000 倍與 3,000 倍的更高能效。
靈汐科技
靈汐科技于 2018 年 1 月在北京成立,聯(lián)合創(chuàng)始人包括清華大學(xué)的世界頂尖類腦計(jì)算研究者。
公司致力于新一代神經(jīng)網(wǎng)絡(luò)處理器(Tianjic) 開發(fā), 特點(diǎn)在于既能夠高效支撐現(xiàn)有流行的機(jī)器學(xué)習(xí)算法(包括 CNN, MLP, LSTM 等網(wǎng)絡(luò)架構(gòu)),也能夠支撐更仿腦的、更具成長潛力的脈沖神經(jīng)網(wǎng)絡(luò)算法; 使芯片具有高計(jì)算力、高多任務(wù)并行度和較低功耗等優(yōu)點(diǎn)。 軟件工具鏈方面支持由 Caffe、 TensorFlow 等算法平臺(tái)直接進(jìn)行神經(jīng)網(wǎng)絡(luò)的映射編譯,開發(fā)友善的用戶交互界面。 Tianjic 可用于云端計(jì)算和終端應(yīng)用場(chǎng)景,助力人工智能的落地和推廣。
啟英泰倫
啟英泰倫于2015年 11月在成都成立,是一家語音識(shí)別芯片研發(fā)商。啟英泰倫的 CI1006是基于 ASIC 架構(gòu)的人工智能語音識(shí)別芯片,包含了腦神經(jīng)網(wǎng)絡(luò)處理硬件單元,能夠完美支持 DNN 運(yùn)算架構(gòu),進(jìn)行高性能的數(shù)據(jù)并行計(jì)算,可極大的提高人工智能深度學(xué)習(xí)語音技術(shù)對(duì)大量數(shù)據(jù)的處理效率。
百度
百度 2017 年 8 月 Hot Chips 大會(huì)上發(fā)布了 XPU,這是一款 256 核、基于 FPGA 的云計(jì)算加速芯片。合作伙伴是賽思靈(Xilinx)。 XPU 采用新一代 AI 處理架構(gòu),擁有 GPU 的通用性和 FPGA 的高效率和低能耗,對(duì)百度的深度學(xué)習(xí)平臺(tái) PaddlePaddle 做了高度的優(yōu)化和加速。據(jù)介紹, XPU 關(guān)注計(jì)算密集型、基于規(guī)則的多樣化計(jì)算任務(wù),希望提高效率和性能,并帶來類似 CPU 的靈活性。
華為

麒麟 970 搭載的神經(jīng)網(wǎng)絡(luò)處理器 NPU 采用了寒武紀(jì) IP,如圖 12 所示。麒麟 970 采用了 TSMC 10nm 工藝制程,擁有 55 億個(gè)晶體管,功耗相比上一代芯片降低 20%。 CPU 架構(gòu)方面為 4 核 A73+4 核 A53 組成 8 核心,能耗同比上一代芯片得到 20%的提升; GPU 方面采用了 12 核 Mali G72 MP12GPU,在圖形處理以及能效兩項(xiàng)關(guān)鍵指標(biāo)方面分別提升 20%和50%; NPU 采用 HiAI移動(dòng)計(jì)算架構(gòu),在 FP16 下提供的運(yùn)算性能可以達(dá)到 1.92 TFLOPs,相比四個(gè) Cortex-A73 核心,處理同樣的 AI 任務(wù),有大約具備 50 倍能效和 25 倍性能優(yōu)勢(shì)。
英偉達(dá)(Nvidia)
英偉達(dá)創(chuàng)立于 1993 年,總部位于美國加利福尼亞州圣克拉拉市。 早在 1999 年, 英偉達(dá)發(fā)明了 GPU,重新定義了現(xiàn)代計(jì)算機(jī)圖形技術(shù),徹底改變了并行計(jì)算。深度學(xué)習(xí)對(duì)計(jì)算速度有非常苛刻的要求, 而英偉達(dá)的 GPU 芯片可以讓大量處理器并行運(yùn)算,速度比 CPU 快十倍甚至幾十倍,因而成為絕大部分人工智能研究者和開發(fā)者的首選。自從 Google Brain 采用 1.6 萬個(gè) GPU 核訓(xùn)練 DNN 模型, 并在語音和圖像識(shí)別等領(lǐng)域獲得巨大成功以來, 英偉達(dá)已成為 AI 芯片市場(chǎng)中無可爭(zhēng)議的領(lǐng)導(dǎo)者。
AMD
美國 AMD 半導(dǎo)體公司專門為計(jì)算機(jī)、 通信和消費(fèi)電子行業(yè)設(shè)計(jì)和制造各種創(chuàng)新的微處理器(CPU、 GPU、 APU、 主板芯片組、 電視卡芯片等),以及提供閃存和低功率處理器解決方案, 公司成立于 1969 年。 AMD 致力為技術(shù)用戶——從企業(yè)、 政府機(jī)構(gòu)到個(gè)人消費(fèi)者——提供基于標(biāo)準(zhǔn)的、 以客戶為中心的解決方案。
2017 年 12 月 Intel 和 AMD 宣布將聯(lián)手推出一款結(jié)合英特爾處理器和 AMD 圖形單元的筆記本電腦芯片。 目前 AMD 擁有針對(duì) AI 和機(jī)器學(xué)習(xí)的高性能 Radeon Instinc 加速卡,開放式軟件平臺(tái) ROCm 等。
Google 在 2016 年宣布獨(dú)立開發(fā)一種名為 TPU 的全新的處理系統(tǒng)。 TPU 是專門為機(jī)器學(xué)習(xí)應(yīng)用而設(shè)計(jì)的專用芯片。通過降低芯片的計(jì)算精度,減少實(shí)現(xiàn)每個(gè)計(jì)算操作所需晶體管數(shù)量的方式,讓芯片的每秒運(yùn)行的操作個(gè)數(shù)更高,這樣經(jīng)過精細(xì)調(diào)優(yōu)的機(jī)器學(xué)習(xí)模型就能在芯片上運(yùn)行得更快,進(jìn)而更快地讓用戶得到更智能的結(jié)果。
在 2016 年 3 月打敗了李世石和 2017 年 5 月打敗了柯杰的阿爾法狗,就是采用了谷歌的 TPU 系列芯片。
Google I/O-2018 開發(fā)者大會(huì)期間,正式發(fā)布了第三代人工智能學(xué)習(xí)專用處理器 TPU 3.0。TPU3.0 采用 8 位低精度計(jì)算以節(jié)省晶體管數(shù)量, 對(duì)精度影響很小但可以大幅節(jié)約功耗、加快速度,同時(shí)還有脈動(dòng)陣列設(shè)計(jì),優(yōu)化矩陣乘法與卷積運(yùn)算, 并使用更大的片上內(nèi)存,減少對(duì)系統(tǒng)內(nèi)存的依賴。 速度能加快到最高 100PFlops(每秒 1000 萬億次浮點(diǎn)計(jì)算)。
高通
在智能手機(jī)芯片市場(chǎng)占據(jù)絕對(duì)優(yōu)勢(shì)的高通公司,也在人工智能芯片方面積極布局。據(jù)高通提供的資料顯示,其在人工智能方面已投資了 Clarifai 公司和中國“專注于物聯(lián)網(wǎng)人工智能服務(wù)” 的云知聲。而早在 2015 年 CES 上,高通就已推出了一款搭載驍龍 SoC 的飛行機(jī)器人——Snapdragon Cargo。
高通認(rèn)為在工業(yè)、農(nóng)業(yè)的監(jiān)測(cè)以及航拍對(duì)拍照、攝像以及視頻新需求上,公司恰好可以發(fā)揮其在計(jì)算機(jī)視覺領(lǐng)域的能力。此外,高通的驍龍 820 芯片也被應(yīng)用于 VR頭盔中。事實(shí)上,高通已經(jīng)在研發(fā)可以在本地完成深度學(xué)習(xí)的移動(dòng)端設(shè)備芯片。
Nervana Systems
Nervana 創(chuàng)立于 2014 年, 公司推出的 The Nervana Engine 是一個(gè)為深度學(xué)習(xí)專門定制和優(yōu)化的 ASIC 芯片。這個(gè)方案的實(shí)現(xiàn)得益于一項(xiàng)叫做 High Bandwidth Memory 的新型內(nèi)存技術(shù), 這項(xiàng)技術(shù)同時(shí)擁有高容量和高速度,提供 32GB 的片上儲(chǔ)存和 8TB 每秒的內(nèi)存訪問速度。該公司目前提供一個(gè)人工智能服務(wù)“in the cloud” ,他們聲稱這是世界上最快的且目前已被金融服務(wù)機(jī)構(gòu)、醫(yī)療保健提供者和政府機(jī)構(gòu)所使用的服務(wù)。 他們的新型芯片將會(huì)保證 Nervana 云平臺(tái)在未來的幾年內(nèi)仍保持最快的速度。
Movidius(被 Intel 收購)
2016 年 9 月, Intel 發(fā)表聲明收購了 Movidius。 Movidius 專注于研發(fā)高性能視覺處理芯片。其最新一代的 Myriad2 視覺處理器主要由 SPARC 處理器作為主控制器,加上專門的DSP 處理器和硬件加速電路來處理專門的視覺和圖像信號(hào)。這是一款以 DSP 架構(gòu)為基礎(chǔ)的視覺處理器,在視覺相關(guān)的應(yīng)用領(lǐng)域有極高的能耗比,可以將視覺計(jì)算普及到幾乎所有的嵌入式系統(tǒng)中。
該芯片已被大量應(yīng)用在 Google 3D 項(xiàng)目的 Tango 手機(jī)、大疆無人機(jī)、 FLIR 智能紅外攝像機(jī)、海康深眸系列攝像機(jī)、華睿智能工業(yè)相機(jī)等產(chǎn)品中。
IBM
IBM 很早以前就發(fā)布過 watson,投入了很多的實(shí)際應(yīng)用。除此之外,還啟動(dòng)了類腦芯片的研發(fā), 即 TrueNorth。TrueNorth 是 IBM 參與 DARPA 的研究項(xiàng)目 SyNapse 的最新成果。
SyNapse 全稱是Systems of Neuromorphic Adaptive Plastic Scalable Electronics(自適應(yīng)可塑可伸縮電子神經(jīng)系統(tǒng),而 SyNapse 正好是突觸的意思),其終極目標(biāo)是開發(fā)出打破馮·諾依曼體系結(jié)構(gòu)的計(jì)算機(jī)體系結(jié)構(gòu)。
ARM
ARM 推出全新芯片架構(gòu) DynamIQ,通過這項(xiàng)技術(shù), AI 芯片的性能有望在未來三到五年內(nèi)提升 50 倍。
ARM的新CPU架構(gòu)將會(huì)通過為不同部分配置軟件的方式將多個(gè)處理核心集聚在一起,這其中包括一個(gè)專門為 AI 算法設(shè)計(jì)的處理器。芯片廠商將可以為新處理器配置最多 8 個(gè)核心。同時(shí)為了能讓主流 AI 在自己的處理器上更好地運(yùn)行, ARM 還將推出一系列軟件庫。
CEVA
CEVA 是專注于 DSP 的 IP 供應(yīng)商,擁有眾多的產(chǎn)品線。其中,圖像和計(jì)算機(jī)視覺 DSP產(chǎn)品 CEVA-XM4是第一個(gè)支持深度學(xué)習(xí)的可編程 DSP,而其發(fā)布的新一代型號(hào) CEVA-XM6,具有更優(yōu)的性能、更強(qiáng)大的計(jì)算能力以及更低的能耗。CEVA 指出,智能手機(jī)、汽車、安全和商業(yè)應(yīng)用,如無人機(jī)、自動(dòng)化將是其業(yè)務(wù)開展的主要目標(biāo)。
MIT/Eyeriss
Eyeriss 事實(shí)上是 MIT 的一個(gè)項(xiàng)目,還不是一個(gè)公司, 從長遠(yuǎn)來看,如果進(jìn)展順利,很可能孵化出一個(gè)新的公司。Eyeriss 是一個(gè)高效能的深度卷積神經(jīng)網(wǎng)絡(luò)(CNN)加速器硬件,該芯片內(nèi)建 168 個(gè)核心,專門用來部署神經(jīng)網(wǎng)路(neural network),效能為一般 GPU 的 10 倍。其技術(shù)關(guān)鍵在于最小化 GPU 核心和記憶體之間交換數(shù)據(jù)的頻率(此運(yùn)作過程通常會(huì)消耗大量的時(shí)間與能量):一般 GPU 內(nèi)的核心通常共享單一記憶體,但 Eyeriss 的每個(gè)核心擁有屬于自己的記憶體。
目前, Eyeriss 主要定位在人臉識(shí)別和語音識(shí)別,可應(yīng)用在智能手機(jī)、穿戴式設(shè)備、機(jī)器人、自動(dòng)駕駛車與其他物聯(lián)網(wǎng)應(yīng)用裝置上。
蘋果
在 iPhone 8 和 iPhone X 的發(fā)布會(huì)上,蘋果明確表示其中所使用的 A11 處理器集成了一個(gè)專用于機(jī)器學(xué)習(xí)的硬件——“神經(jīng)網(wǎng)絡(luò)引擎(Neural Engine) ”, 每秒運(yùn)算次數(shù)最高可達(dá)6000 億次。這塊芯片將能夠改進(jìn)蘋果設(shè)備在處理需要人工智能的任務(wù)時(shí)的表現(xiàn),比如面部識(shí)別和語音識(shí)別等。
三星
2017 年,華為海思推出了麒麟 970 芯片,據(jù)知情人士透露,為了對(duì)標(biāo)華為,三星已經(jīng)研發(fā)了許多種類的人工智能芯片。 三星計(jì)劃在未來三年內(nèi)新上市的智能手機(jī)中都采用人工智能芯片,并且他們還將為人工智能設(shè)備建立新的組件業(yè)務(wù)。三星還投資了 Graphcore、深鑒科技等人工智能芯片企業(yè)。
3、技術(shù)趨勢(shì)

目前主流 AI 芯片的核心主要是利用 MAC(Multiplier and Accumulation, 乘加計(jì)算) 加速陣列來實(shí)現(xiàn)對(duì) CNN(卷積神經(jīng)網(wǎng)絡(luò))中最主要的卷積運(yùn)算的加速。這一代 AI 芯片主要有如下 3 個(gè)方面的問題。
(1)深度學(xué)習(xí)計(jì)算所需數(shù)據(jù)量巨大,造成內(nèi)存帶寬成為整個(gè)系統(tǒng)的瓶頸,即所謂“memory wall” 問題。
(2)與第一個(gè)問題相關(guān), 內(nèi)存大量訪問和 MAC陣列的大量運(yùn)算,造成 AI芯片整體功耗的增加。
(3)深度學(xué)習(xí)對(duì)算力要求很高,要提升算力,最好的方法是做硬件加速,但是同時(shí)深度學(xué)習(xí)算法的發(fā)展也是日新月異,新的算法可能在已經(jīng)固化的硬件加速器上無法得到很好的支持,即性能和靈活度之間的平衡問題。
因此,可以預(yù)見下一代 AI 芯片將有如下的五個(gè)發(fā)展趨勢(shì)。
(1)更高效的大卷積解構(gòu)/復(fù)用
在標(biāo)準(zhǔn) SIMD 的基礎(chǔ)上, CNN 由于其特殊的復(fù)用機(jī)制,可以進(jìn)一步減少總線上的數(shù)據(jù)通信。而復(fù)用這一概念,在超大型神經(jīng)網(wǎng)絡(luò)中就顯得格外重要。 如何合理地分解、 映射這些超大卷積到有效的硬件上成為了一個(gè)值得研究的方向,
(2)更低的 Inference 計(jì)算/存儲(chǔ)位寬
AI 芯片最大的演進(jìn)方向之一可能就是神經(jīng)網(wǎng)絡(luò)參數(shù)/計(jì)算位寬的迅速減少——從 32 位浮點(diǎn)到 16 位浮點(diǎn)/定點(diǎn)、 8 位定點(diǎn),甚至是 4 位定點(diǎn)。在理論計(jì)算領(lǐng)域, 2 位甚至 1 位參數(shù)位寬,都已經(jīng)逐漸進(jìn)入實(shí)踐領(lǐng)域。
(3)更多樣的存儲(chǔ)器定制設(shè)計(jì)
當(dāng)計(jì)算部件不再成為神經(jīng)網(wǎng)絡(luò)加速器的設(shè)計(jì)瓶頸時(shí),如何減少存儲(chǔ)器的訪問延時(shí)將會(huì)成為下一個(gè)研究方向。通常,離計(jì)算越近的存儲(chǔ)器速度越快,每字節(jié)的成本也越高,同時(shí)容量也越受限,因此新型的存儲(chǔ)結(jié)構(gòu)也將應(yīng)運(yùn)而生。
(4)更稀疏的大規(guī)模向量實(shí)現(xiàn)
神經(jīng)網(wǎng)絡(luò)雖然大,但是,實(shí)際上有很多以零為輸入的情況, 此時(shí)稀疏計(jì)算可以高效的減少無用能效。來自哈佛大學(xué)的團(tuán)隊(duì)就該問題提出了優(yōu)化的五級(jí)流水線結(jié),在最后一級(jí)輸出了觸發(fā)信號(hào)。在 Activation層后對(duì)下一次計(jì)算的必要性進(jìn)行預(yù)先判斷,如果發(fā)現(xiàn)這是一個(gè)稀疏節(jié)點(diǎn),則觸發(fā) SKIP 信號(hào),避免乘法運(yùn)算的功耗,以達(dá)到減少無用功耗的目的。
(5)計(jì)算和存儲(chǔ)一體化
計(jì)算和存儲(chǔ)一體化(process-in-memory)技術(shù),其要點(diǎn)是通過使用新型非易失性存儲(chǔ)(如 ReRAM)器件,在存儲(chǔ)陣列里面加上神經(jīng)網(wǎng)絡(luò)計(jì)算功能,從而省去數(shù)據(jù)搬移操作,即實(shí)現(xiàn)了計(jì)算存儲(chǔ)一體化的神經(jīng)網(wǎng)絡(luò)處理,在功耗性能方面可以獲得顯著提升。
結(jié)尾:

近幾年,AI技術(shù)不斷取得突破性進(jìn)展。作為AI技術(shù)的重要物理基礎(chǔ),AI芯片擁有巨大的產(chǎn)業(yè)價(jià)值和戰(zhàn)略地位。
但從大趨勢(shì)來看,目前尚處于AI芯片發(fā)展的初級(jí)階段,無論是科研還是產(chǎn)業(yè)應(yīng)用都有巨大的創(chuàng)新空間。
現(xiàn)在不僅英偉達(dá)、谷歌等國際巨頭相繼推出新產(chǎn)品,國內(nèi)百度、阿里等紛紛布局這一領(lǐng)域,也誕生了寒武紀(jì)等AI芯片創(chuàng)業(yè)公司。
在CPU、GPU等傳統(tǒng)芯片領(lǐng)域與國際相差較多的情況下,中國AI芯片被寄望能實(shí)現(xiàn)彎道超車。

