131 1300 0010
本期和大家聊的是剛剛在2月份拿到FAST 2018最佳論文獎的一篇文章。它討論了實現一種支持保序IO操作的設備會帶來哪些好處,目前的Linux內核里處理FLUSH、FUA的方式可以參見 https://lwn.net/Articles/400541/
作者
朱延海,Linux系統工程師,來自阿里云系統組。
阿里云系統團隊,是由原淘寶內核組擴建而成,2013年淘寶內核組響應阿里巴巴集團的號召,整建制轉入阿里云,開始為云計算底層系統構建完善的系統支持。 阿里云系統團隊是由一群具有高度使命感和自我追求的內核開發人員組成,團隊中的大多數人,都是活躍的社區內核開發人員。目前的工作領域主要涉及(但不限于) Linux內核的內存管理、文件系統、網絡和內核維護構建,以及和內核相關聯的用戶態庫和工具。如果你對我們的工作很感興趣,歡迎加入我們,請將簡歷發送至 tao.ma at linux.alibaba.com或者 boyu.mt at alibaba-inc.com。
概述
現代高速Flash設備的性能訣竅在于充分提高請求處理的并行度(scale-out),而并非無限地降低其延遲(scale-up)—例如,使用多通道控制器(multi-channel controllers)、更大的緩存以及更深的命令隊列,這些都是用來提高并行度的有效辦法。同時,寫一個flash cell所需要的時間一直沒有什么變化,近來甚至有變差的趨勢。在大部分情況下,用戶對此并不在意,也感覺不到—除非你的應用希望它發出的一系列請求是保序的(guarantee ordering),這也就是本文所要重點討論的問題:
“在目前的設備上,為請求保序是通過一種代價很高的辦法來實現的:把排在請求X前邊的所有請求都發出去,然后等待它們全部完成、持久化并返回,然后才發射請求X,這時我們就可以說X前邊的請求和X之間建立了明確的先后順序關系。我們把這種機制叫做Transfer-and-Flush。”
顯而易見,當你使用Transfer-and-Flush機制時,設備的并行度會大大降低,因此帶來最終性能的降低,設備越是依賴高并行度來攫取性能,這種做法就越是令人無法接受。例如,在一個智能手機的單通道SSD上,保序寫請求的IOPS是無序寫請求的20%,對于32通道SSD,這一比例降低至1%。在目前的Linux內核中,文件系統若真的想執行一系列保序請求,使用的機制也是Transfer-and-Flush。然而,通過Transfer-and-Flush來保序顯然殺傷力過大了:首先,也許文件系統原本只想讓兩個單個請求之間是有序的,但卻不得不使得由flush分隔的兩組操作集合之間變得有序,而這每一個集合里都可能包含了大量不需要保序的請求;其次,這么做不僅實現了保序,同時還提供了同步的持久化保證,這并不是保序想要的—當一個上層應用發出兩個保序的請求A1和A2時,它對于A1和A2具體何時被持久化并沒有什么期待,可以是異步的,它唯一的要求是一但持久化動作開始,A1的持久化必須發生在A2之前。
本文的作者提出了一種被稱為Barrier-enabled IO stack的方案,這一方案不依賴Transfer-and-Flush,文件系統也就無需停下來等待前邊的請求成功返回。這一方案得到的性能提升相當驚人:
“SQlite服務器場景性能提升270%,手機場景性能提升75%;實現了Barrier-enabled IO stack的BarrierFS在MySQL場景性能指標是EXT4的43倍,在SQLite場景性能指標是EXT4的73倍”
下邊我們來介紹下作者的方案
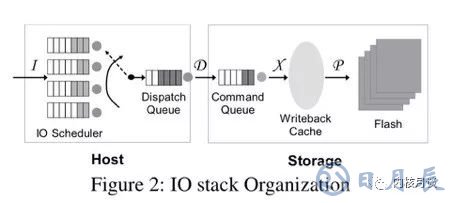
我們知道,現代IO stack天生就是亂序的。試想文件系統發射出來的一簇請求在下邊的路徑里會經歷些什么:
IO調度器會對請求重排列,還有可能合并請求
設備上的控制器收到請求后放到自己內部的命令隊列里,這時它也可以隨意改變請求順序。設備內部的錯誤、超時、重傳等等也都有可能對請求實際執行的順序產生影響
現代設備內部通常也像文件系統一樣,有數據塊和元數據塊,有自己的journal。請求抵達存儲設備內部之后,最終對用戶可見、對用戶有意義的持久化“順序”不光是由數據塊的持久化順序決定,同時也受那些元數據的持久化順序影響,而這兩者并不一定是相同的。
因此,多數操作系統的IO stack都包含了一個從硬盤時代流傳下來的設計假設:上位機不能控制持久化順序
“現代IO stack設計中的一個基本假設就是上位機不能真正地控制到數據的持久化順序”
因此,一但上位機確實需要控制持久化順序時,就只能使用昂貴的Transfer-and-Flush機制了:如果請求a需要排在請求b之前完成,那么把請求a發到存儲設備之后,上位機就首先需要等設備報告a徹底完成,然后發一個flush命令并等待flush完成(以防設備上的cache造成亂序),然后才發請求b。
以EXT4的默認工作模式Ordered模式為例,當它提交一個journal transaction時,它需要執行兩次寫:第一次寫journal descriptor和log blocks(JD),第二次寫commit block(JC)。JD必須先于JC完成持久化。在transaction的層面上看,各個transaction之間也必須是有序的,排在前邊的transaction一定要比排在后邊的transaction先完成持久化,否則文件系統執行故障恢復時就有崩潰的可能。 為了把保序語義引入IO stack,作者顯然需要自底向上把這個語義貫穿到整個IO stack中去。下邊具體介紹一下作者的工作。
帶barrier的保序塊設備
“給設備加入barrier指令支持后,上位機就不再需要通過顯式地刷cache來保證請求順序了。當設備收到barrier指令時,它會確保排在barrier前的所有指令—可能是寫也可能是讀—都執行完畢、完成數據傳輸后,才開始執行排在barrier后邊的指令。”
論文的作者把他提出的這種barrier實現成了SCSI命令的一個附加屬性,而不是一條獨立的SCSI命令。設備具體實現barrier支持的方法有很多,對于本身已經帶有一個大電容,寫操作返回時就可以保證持久化的那些設備,可以認為它們天生對于收到的寫請求就是保序的,因此只要在設備上邊的各個層次能夠保證提交順序,整條鏈路就直接可以做出保序的承諾,因此對于這些設備沒什么需要修改的。對于其他設備,在設備內部實現保序其實和之前在整個IO stack上實現保序的邏輯基本是一樣的,要么確保writeback cache按順序回寫、要么在回寫時引入事務機制、要么實現按順序recovery。論文對于具體如何實現這種帶barrier支持的存儲設備一筆帶過,并表示這不是重點,作者認為論文的重點在于說明一但擁有此種設備會帶來多大好處,至于如何實現這種設備那是純粹的engineering efforts,不再過多考慮。
總之,一但擁有這種設備,就可以實現請求的保序發送:
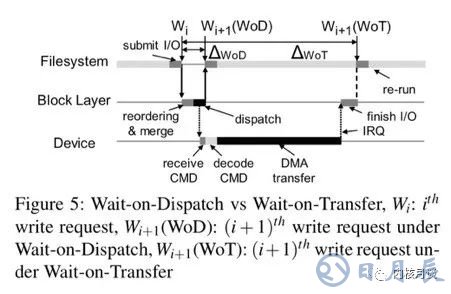
“保序發送是本文的重要創新之處,上層的文件系統對于需要保序的請求可以帶上barrier標志,只要注意在發送時不把它們重排序就行,不再需要等待flush。由下邊的存儲設備來保證帶barrier標志請求的持久化順序與它們的發送順序相同。我們把這種機制叫做wait-on-dispatch”
顯然,wait-on-dispatch比wait-on-transfer的成本要小很多,如下圖所示:
scsi layer
我們沿著從下往上的方向繼續向上層走,當設備實現了barrier支持之后,緊接著需要修改的是scsi層。在這里作者利用了scsi層已有的command priority level機制,按照scsi規范,命令可以分成三種:head of the queue(收到命令時要把它插入到隊列頭上)、ordered(收到命令時要把它插入到隊列尾部)、simple(命令可以插入到隊列中任意位置,但不能放在head of the queue命令或ordered命令的前邊)。因此,只需要把barrier命令打上ordered屬性發送,把其他寫請求打上simple屬性發送,就天然地可以在scsi層上保證barrier語義了。
“在目前的塊設備層實現中,ordered命令很少使用,這是因為當整個IO stack尚且不能做到保序發送時,單獨在scsi層控制命令的發送順序沒有什么意義。然而,當我們在全路徑上引入barrier語義后,scsi層的ordered命令就開始扮演重要的角色了”
epoch-based IO scheduler
在解決了scsi層的問題后,作者沿著IO路徑繼續往上走,對IO調度器加以修改,引入了所謂的epoch-based scheduling:
需要保序的寫操作,帶有REQ_ORDERED標志
一對REQ_BARRIER之間的所有RED_ORDERED寫構成一個epoch
兩個epoch之間整體上的提交是保序的,即第一個epoch的所有寫請求提交結束后,才提交第二個epoch里的寫請求
一個epoch內部的REQ_ORDERED寫之間可以自由重排序
不帶REQ_ORDERED的寫請求可以任意自由跨epoch重排序
這樣作者就進一步解決了barrier殺傷力過大的問題—只有明確表示需要保序的寫請求,其提交順序才受barrier約束。
Barrier-enabled filesystem
IO調度器理順之后,作者繼續向上走,開始修改文件系統,提出了barrier-enabled filesystem(BFS)的概念,BFS引入了兩個新的原語:fbarrier()和fdatabarrier(),它們分別是fsync()和fdatasyn()在保序這個意義上的對應產物,即是說,當你調用它們時,它們會確保排在調用點之前的所有寫操作(或者所有數據寫操作)一定比排在它們之后的所有寫操作先完成持久化,然而對于具體何時會完成持久化不做保證。另外,作者也修改了ext4的journal以使它利用上新的barrier機制:
“利用底層設備提供的保序語義,我們就可以把一次journal提交過程中的控制平面活動(寫請求的提交)和數據平面活動(數據及journal的持久化)分開處理,我們建立兩個線程,一個負責保序提交請求,另一個負責等待它們完成。我們把這種機制叫做Dual Mode Journaling”
效果評估
原文中的第6小節也包括了塊設備層和文件系統層的性能測試,不過我們這里直接關注最終的應用性能提升。
對于服務器負載,作者跑了varmail(varmail發的fsync非常多),還有MySQL上的OLTP-insert測試。作者把這里的對比測試細分成了兩種情況,第一種是所謂的durability guarantee測試,在這個測試里應用代碼完全不改,用BarrierFS和標準的EXT4做對比,這是為了說明利用了barrier語義后fsync()本身的性能提升;第二種是所謂的ordering guarantee測試,在這個測試里作者跑了BarrierFS、OptFS和EXT4三種文件系統(前兩種支持barrier語義),并在前兩種文件系統上把應用的fsync()換成fdatabarrier()和osync()(osync是OptFS里的barrier操作),對于EXT4則加上nobarrier參數。這一測試是為了說明wait-on-dispatch比wait-on-transfer的優越之處,注意這里作者實際上做了一個不切實際的假定,須知有時應用調用fsync()時確實是想保證其持久性的,并非每一處fsync()都可以換成fdatabarrier(),具體要如何修改應用必須結合應用的具體上下文。第二個測試的結果只能說明結合應用具體場景,去掉overkill的持久化約束后性能提升的上限會是多少。
在durability guarantee測試中,BarrierFS為varmail帶來了10%-60%的性能提升,為MySQL帶來了12%的性能提升;在ordering guarantee測試中,BarrierFS帶來了36倍性能提升,為MySQL帶來了43倍性能提升。
對于移動設備負載,作者測試了Sqlite,durability guarantee帶來了75%性能提升,ordering guarantee帶來了2.8倍性能提升。
結語
“為高并發Flash設備設計一個支持barrier語義的IO stack會帶來極大的性能優勢 …… 這種barrier語義已經日漸成為一種必須品,我們建議從移動端到服務端的各種Flash設備廠商考慮支持barrier語義”

